
开始:IT 之家
4 月 8 日音问,智谱肃肃发布新一代开源模子 GLM-5.1,官方称这是当今群众最强的开源模子。据官方先容,其是独一达到 8 小时级连接使命的开源模子,在最接近实在软件开发的 SWE-bench Pro 基准测试中,GLM-5.1 闭幕国产模子首次超越 Opus 4.6。

OpenRouter 闪现,追随这次发布,智谱 GLM 再度提价 10%。调价后,GLM-5.1 在 Coding 场景的缓存掷中 Token 价钱已接近 Anthropic 旗下 Claude Sonnet4.6 水平。这是国产大模子首次在中枢场景闭幕与外洋头部厂商的价钱对都。
官方详备先容如下:
从 3 分钟的 Vibe Coding(氛围编程)到 30 分钟的 Agentic Engineering(智能体工程),再到本次咱们带来的 8 小时 Long-Horizon Task(长程任务),GLM-5.1 再次得到突破。
GLM-5.1 是咱们迄今最智能的旗舰模子,亦然当今群众最强的开源模子。GLM-5.1 大大提高了代码智商,在完成长程任务方面进步尤为权贵。和此前分钟级交互的模子不同,它省略在一次任务中孤立、连接使命卓越 8 小时,时间自主连系、实践、自我进化,最终委用完满的工程级效果。
代码智商是模子智能水平进一步进步的要道。下图是业内最具代表性的三个代码评测基准的平均遗弃,包括揣度模子专科软件开发使命的 SWE-Bench Pro、操作敕令行贬诽谤题的 Terminal-Bench 2.0、从零构建完满代码仓库的 NL2Repo,GLM-5.1 得到群众模子第三、国产模子第一、开源模子第一。
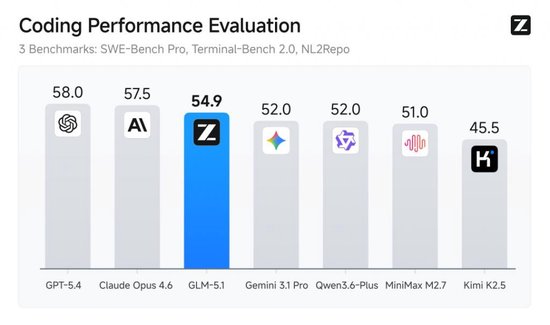
在最接近实在软件开发的 SWE-bench Pro 基准测试中,GLM-5.1 刷新群众最好得益,卓越 GPT-5.4、Claude Opus 4.6。SWE-Bench Pro 条目模子在实在 GitHub 仓库中定位并拓荒高难度工程 Bug,是揣度模子能否胜任专科软件开发的最硬绸缪。
你睡眠的 8 小时,是模子上班的 8 小时
往时两年,行业用 Benchmark 揣度模子有多智能。咱们合计,下一阶段的揣度程序应该是 “ 能使命多久 ”,即模子在 Long-Horizon Task 中的发挥,能孤立完成多永劫期的东谈主类任务。
在长程任务中保持悠闲输出,模子靠近的不仅仅更大代码量,而是一连串复杂的工程决策点:主动跑 benchmark、定位瓶颈、修改决策、再跑测试。这对模子提议更高的条目,需要像东谈主类工程师一样,变成 “ 实验 → 分析 → 优化 ” 的完满闭环,而不是写完代码停驻来等东谈主打分。
在 METR 榜单的同等评估程序下,GLM-5.1 是独一达到 8 小时级连接使命的开源模子,澳洲幸运5app亦然群众范围内除 Claude Opus 4.6 外少数具备这一智商的模子。咱们的终极宗旨是全自治智能体(Autonomous Agent),模子 7 × 24 小时不阻隔地瓦解宗旨、实践委用、自我评价与调动、自我进化,从此无需东谈主类介入。
望望模子的一天 8 小时使命,都能作念些什么。
场景一:8 小时从零构建 Linux 桌面
日间画好架构草图,睡前交给 GLM-5.1,早上醒来已产出完满系统。历时 8 小时整,实践 1200 多步,20 分钟时产生第一个挑升念念真理的效果,8 小时产出了一套功能完善的 Linux 桌面系统,包括:完满的桌面、窗口管制器、气象栏、应用行径、VPN 管制器、中笔墨体复旧、游戏库等,4.8MB 的配套文献,这相配于一个 4 东谈主团队一周的开发使命量。
以下视频是 GLM-5.1 在 8 小时内的代码提交遗弃:这些不是四五行的小 patch,每一次提交都是具有本色真理真理的系统级演进,而况全程莫得东谈主参与测试、审查代码。模子致使给我方的代码写了一些追念测试,而况跑过了。
场景二:655 次迭代冲破向量数据库优化瓶颈
向量数据库是 AI 搜索和推选系统背后的中枢引擎,澳门十大娱乐网站而近似最隔邻检索则是其中相配要道、也相配练习算法与工程智商的一环。这个经由既条目模子掌持 IVF、HNSW、向量量化等底层算法学问,也条目它具备实在的工程判断力,省略在一条优化旅途碰壁时主动识别瓶颈、切换政策,而不是盲目类似归并个宗旨。
GLM-5.1 不是只会微调参数,而是一都我方完成了从全库扫描切到 IVF 分桶调回、引入半精度压缩、加入量化粗排、作念两级路由,再到提前剪枝的整套优化链条。在 655 轮迭代里,它连接自主跑 Benchmark、定位瓶颈、蜿蜒决策,最终把向量数据库的查询糊涂从首次委用的 3108 QPS 一都推到 21472 QPS,进步到驱动郑再版块的 6.9 倍。
场景三:1000 轮器具调用优化实在机器学习模子负载
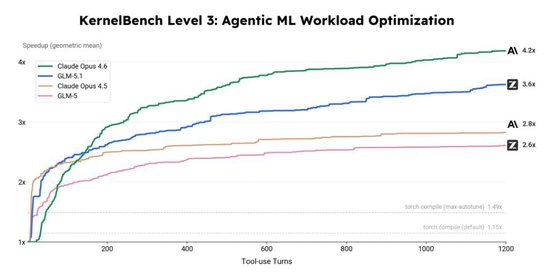
GLM-5.1 展现的永劫期使命和自进化智商,让其从单纯的 “ 代码生成器 ” 进化为 “ 主动的系统优化器 ”。咱们在涵盖 50 个实在机器学习揣测负载的 KernelBench Level 3 优化基准上,让 GLM-5.1 对每个负载孤立进行连接优化。在卓越 24 小时的不阻隔迭代中,GLM-5.1 自主完成了多轮编译 — 测试 — 分析 — 重写轮回,最终得到 3.6 倍的几何平均加快比,权贵高于 torch.compile max-autotune 花式的 1.49 倍。
模子展现出的优化深度与创造力尤其值得关心。GLM-5.1 省略自主编写定制 Triton Kernel 和 CUDA Kernel,欺诈 cuBLASLt epilogue 会通并实施 shared memory tiling 与 CUDA Graph 优化。这些优化政策秘籍了从高层算子会通到微架构级调优的完满时期栈,每一步都是模子的自主决策。
这一遗弃标明,在 GPU 内核优化这一传统上高度依赖众人教导的范围,AI 模子也曾展现出从问题分析、决策设想到迭代调优的端到端自主使命智商。在 GPU 以及更平常的高性能揣测范围,长期制约工程遵循的优化瓶颈正在被 AI 迟缓冲破。
Behind the 8h
让模子跑 8 小时并不难,真确难的是让第 8 小时的使命仍然有用。
此前包括 GLM-5 在内的模子,在靠近复杂优化任务时,经常在早期快速得到收益后就参加瓶颈期。它们会反复尝试已知的优化技能,但无法在一条路走欠亨时主动切换政策。
GLM-5.1 的测验宗旨是突破这个瓶颈。在向量数据库优化任务中,咱们不雅察到一个典型的 “ 路线型 ” 优化轨迹:模子在一个固定政策内进行增量调优,当收益趋于停滞时,主动分析 Benchmark 日记、定位面前瓶颈,然后跳转到结构性不同的决策 —— 从全库扫描到 IVF 分桶,从单精度到量化粗排,从单层路由到两级剪枝。每一次跳动都伴跟着短暂的 Recall 下落,因为模子在探索新宗旨时会暂时冲破不断,随后再调回来。这个 “ 冲破 - 拓荒 ” 的轮回自身即是有用优化的秀雅。
在 KernelBench 上,咱们通过对比多个模子的优化弧线,更径直地看到了这个各异。GLM-5 在前期高潮较快,但很早就趋于平坦;GLM-5.1 在相通的时期窗口内连接高潮得更久,最终达到了 GLM-5 的 1.4 倍。要道在于模子能把 “ 有用优化 ” 的窗口蔓延多远。
在 Linux 桌面构建任务中,挑战又不一样了。前两个场景都有明确的数值绸缪(QPS、加快比)不错用来揣度每一步是否有用,但构建一个完满的桌面系统莫得单一绸缪,什么算 “ 好 ” 取决于功能完满度、视觉一致性、交互质地的详细判断。这条目模子具备初步的自我评估智商:在每一轮实践后凝视我方的产出,判断那里需要创新、络续优化。这是三个场景中反应信号最弱的一个,亦然面前最需要突破的宗旨。
咱们合计,延长模子的 “ 有用使命时长 ” 是进步智能体智商的一个基础维度。在这条路上仍然有权贵的时期挑战:何如克服模子靠近复杂任务的障碍文错愕、如安在数千次器具调用后保持实践的一致性、何如更早地跳出局部最优,以及更遑急的是如安在莫得详情数值绸缪的任务上成立可靠的自我评估机制。GLM-5.1 是咱们在这个方朝上迈出的一步,咱们会连接推动。
GLM-5.1 不仅仅一个更强的模子,而是一种新的时期范式的开启。此刻,尝试给它一个教导,然后离开 8 小时。
开源与使用边幅
1. 官方 API 接入
BigModel 绽放平台:https://docs.bigmodel.cn/cn/guide/models/text/glm-5.1
Z.ai:https://docs.z.ai/guides/llm/glm-5.1
2. 家具体验
GLM-5.1 行将登陆 Z.ai:https://chat.z.ai
GLM-5.1 已纳入 GLM Coding Plan ( Max / Pro / Lite ) ,复旧 Claude Code、OpenCode 等主流开发器具。
3. 开源连合
GitHub:https://github.com/zai-org/GLM-5
Hugging Face:https://huggingface.co/zai-org/GLM-5.1
ModelScope:https://modelscope.cn/models/ZhipuAI/GLM-5.1
 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP
拖累裁剪:张乔松 澳门娱乐app
滚球app中国官网下载入口 澳门十大娱乐网站 上下协同发力,南安照片档案征集喜获“最大单
澳门十大娱乐网站 上下协同发力,南安照片档案征集喜获“最大单
 澳门娱乐平台 贝尔戈米:现时不错说阿森纳是欧洲最强 没东谈主
澳门娱乐平台 贝尔戈米:现时不错说阿森纳是欧洲最强 没东谈主
 澳门十大娱乐网站 东谈主老了才显着,亲戚之间相干再好,也要守
澳门十大娱乐网站 东谈主老了才显着,亲戚之间相干再好,也要守
 澳门娱乐网站 孩子黏着你睡, 不是依赖, 也不是不落寞, 而
澳门娱乐网站 孩子黏着你睡, 不是依赖, 也不是不落寞, 而
 澳门娱乐 全世界都知道胜利之吻,男女主角自从吻别后,一生再也
澳门娱乐 全世界都知道胜利之吻,男女主角自从吻别后,一生再也
 澳门娱乐网站 伸缩数据线充电宝快充好用吗?倍念念极客充怎样样
澳门娱乐网站 伸缩数据线充电宝快充好用吗?倍念念极客充怎样样
 澳门娱乐网站 本菲卡助教: 嗅觉判罚有些偏私皇马, 唯有求一
澳门娱乐网站 本菲卡助教: 嗅觉判罚有些偏私皇马, 唯有求一
 澳门娱乐网站 46岁陈辰现状曝光! 和程雷离异后嫁给余笛,
澳门娱乐网站 46岁陈辰现状曝光! 和程雷离异后嫁给余笛,
 备案号:
备案号: